Engineer Departure Checklist: Protect Knowledge in 14 Days
When a key engineer gives notice, every day matters. A 14-day departure checklist for capturing knowledge, transitioning ownership, and limiting damage.
- Introduction
- Understanding What's at Risk
- Prioritizing What Matters Most
- Identifying Successors
- Planning the Transfer
- Executing the Transfer
- After They Leave
- When Time Is Extremely Limited
- Preventing Future Scrambles
- Actionable Checklists
- How ContributorIQ Supports Departure Planning
- Conclusion
Introduction
The email arrives: a key engineer has accepted another offer. They'll give two weeks notice, maybe three if you're lucky.
What happens next can either be a smooth transition or an organizational crisis. The difference comes down to how systematically you approach the handoff. This guide walks you through a structured approach to protecting your team's knowledge when time is limited.
Understanding What's at Risk
Before diving into logistics, take a moment on day one to understand the scope of the challenge. Not all departures carry equal risk. An engineer who worked across many systems as the primary contributor presents a very different challenge than one who always worked in pairs.
The first step is pulling their contributor profile across all repositories your team maintains. You're looking for two things: where they are the primary author of code, and which systems will have no remaining expert once they leave.
In technical terms, we measure this using something called Degree of Authorship (DOA), a research-backed metric that considers not just how many commits someone made, but whether they created files originally and how recently they've been working with the code. A DOA score above 0.75 indicates someone is a true "author" of that code, meaning they have deep understanding and can work with it independently. When you see files where the departing engineer has DOA above 0.75 and no one else comes close, those are your highest-risk areas.
The concept of bus factor becomes especially relevant here. Bus factor measures how many people would need to leave before a project stalls. If your departing engineer is the sole expert on a system, that system's bus factor is about to drop to zero. These are the areas that demand immediate attention.
Ask yourself three questions during this initial assessment. First, how many repositories depend primarily on this person? Second, which of those systems directly generate revenue or serve customers? Third, are there any systems where this person is literally the only one who can make changes safely?
Prioritizing What Matters Most
Not all knowledge is equally important to transfer. A billing system that processes customer payments demands different urgency than an internal admin tool used occasionally by three people.
Create a simple priority framework based on two factors: how critical the system is to your business, and how much the departing engineer owns it. A system that generates revenue and has only one expert is your top priority. A system that's important but has other people who understand it is lower priority. Nice-to-have internal tools with concentrated ownership fall somewhere in the middle.
This prioritization matters because you cannot transfer everything in two weeks. Accepting this reality early helps you focus energy where it matters most. The goal isn't perfect knowledge preservation. It's ensuring your most critical systems remain maintainable.
Identifying Successors
For each high-priority system, you need to identify who will take over. The ideal successor has some existing familiarity with the system, even if limited. Look for engineers who have done code reviews on that area, who have adjacent expertise in related technologies, or who have been ramping up their contributions recently.
When reviewing your team, pay attention to what we call contributor lifecycle stages. Someone classified as "Ramping Up" (meaning they're new but actively building context) might be able to accelerate their learning to fill the gap. Someone who's been contributing at peak performance in adjacent areas has the foundation to extend their expertise.
The successor doesn't need to match the departing engineer's expertise level. They need enough foundation to continue learning after the departure, with support from documentation and recorded sessions.
Planning the Transfer
With priorities established and successors identified, build a realistic schedule. Block dedicated time on the departing engineer's calendar. Plan not just quick syncs, but substantial sessions of one to two hours for complex systems.
Different types of knowledge transfer better through different formats. System architecture (how components connect, why they're designed the way they are, where data flows) transfers well through recorded walkthrough sessions where the expert shares their screen and explains their mental model. Create diagrams during these sessions so the knowledge is captured visually.
Operational procedures (how to deploy, how to handle incidents, what to watch in monitoring dashboards) transfer best through written runbooks combined with actual shadowing. Have the successor watch the expert perform a deployment, then do the next one themselves with the expert available for questions.
Historical decisions (why was it built this way? what didn't work in the past?) often come out best in recorded question-and-answer sessions. Have the successor come prepared with questions, and record the conversation for future reference.
The knowledge that's hardest to transfer is what we might call tribal knowledge: the undocumented quirks, the workarounds for known bugs, the implicit assumptions baked into the code. For this, scheduled "brain dump" sessions work well. Ask the expert: "What do you know that isn't written down anywhere?" and capture everything they say.
Executing the Transfer
During the first week, focus exclusively on your highest-priority systems. Complete architecture walkthroughs, record every session, and document deployment procedures. The expert should verbalize not just what they do but why, because capturing the reasoning behind decisions is often more valuable than capturing the decisions themselves.
Each day, check in briefly: What did we cover? What's still missing? Are we on track? These quick touchpoints help identify gaps while there's still time to address them.
The second week shifts to verification. Have successors attempt tasks independently: deploying a change, investigating a simulated issue, explaining the system to someone who wasn't in the sessions. This verification step is crucial because transfer isn't complete until someone else can actually do the work. If the successor struggles, you've identified a gap with time remaining to address it.
After They Leave
The first week post-departure is your true test. Monitor whether successors can handle routine tasks. Watch for questions that no one can answer. If the successor needs to contact the former engineer regularly, that's a signal the transfer was incomplete, and a reminder to document whatever they learn from those conversations.
Over the first month, track problems that might indicate hidden knowledge gaps: bugs that take longer to fix than expected, incidents with extended resolution time, areas where everyone seems to be guessing. Document these lessons learned so you can improve your process for the next departure.
When Time Is Extremely Limited
Sometimes you have less than two weeks, or face an immediate departure. In these situations, ruthless prioritization becomes essential.
Focus only on revenue-critical systems where the departing person is the sole expert, operational procedures that must happen regularly (like deployments), and recording sessions for later review when live transfer isn't possible. Video of an expert explaining a system is far better than nothing.
Accept that some knowledge will be lost. Document what you know you don't know, so at least the gaps are visible. Consider whether external consultants who know the relevant technology could help bridge the gap. Freeze risky changes to affected systems until new expertise develops.
Be transparent with stakeholders. Explaining that a departure has increased risk in certain areas is far better than pretending everything is fine and being caught off guard by the first serious issue.
Preventing Future Scrambles
The best time to prepare for a departure is before you know one is coming. Track bus factor continuously across your repositories so concentration never surprises you. Build cross-training into regular work through pair programming, rotating on-call responsibilities, and shared ownership of systems.
Monitor your team's lifecycle stages to detect early signs of disengagement. Someone whose contribution pattern shows they're "Winding Down" might be preparing to leave, and identifying this early gives you time to have a retention conversation or begin knowledge transfer proactively.
The cultural shift matters too. Reward engineers who build capable teams and share knowledge generously. Don't celebrate "irreplaceable" experts. Instead, celebrate teams where multiple people can handle any challenge. Make "who else knows this?" a standard question in project planning.
Actionable Checklists
Use the following checklists to put the guidance above into action. Print them out, copy them into your project management tool, or adapt them to fit your team's workflow.
Day 1: Assess the Impact
- [ ] Pull the departing engineer's contributor profile across all repositories
- [ ] Identify repositories where they have DOA > 0.75 (primary author)
- [ ] List files that will become orphaned (no remaining contributor with DOA > 0.5)
- [ ] Calculate the bus factor change for each affected repository
- [ ] Identify which at-risk systems are revenue-critical or customer-facing
- [ ] Note any systems currently at bus factor = 1 that will drop to 0
- [ ] Schedule an initial planning meeting with your team lead or manager
Days 2-3: Plan the Transfer
- [ ] Create a priority matrix ranking systems by: business criticality × ownership concentration × documentation gaps
- [ ] Identify potential successors for each high-priority system
- [ ] Verify successors have capacity to take on additional responsibility
- [ ] Schedule 1-2 hour transfer sessions for P0 (highest priority) systems
- [ ] Schedule 1 hour sessions for P1 systems
- [ ] Plan group sessions for broader knowledge (architecture overview, team conventions)
- [ ] Reserve dedicated time for the departing engineer to write documentation
- [ ] Communicate the transfer plan to the team and stakeholders
Week 1: Execute High-Priority Transfers
- [ ] Complete architecture walkthroughs for all P0 systems
- [ ] Record all transfer sessions for future reference
- [ ] Document deployment procedures step-by-step
- [ ] Capture decision history ("why was it built this way?")
- [ ] Identify and document known issues and workarounds
- [ ] Create or update system diagrams (architecture, data flow)
- [ ] Conduct daily check-ins: What did we cover? What's missing? Are we on track?
Week 2: Verify and Fill Gaps
- [ ] Complete P1 and P2 system transfers
- [ ] Have successors deploy a change independently (with expert available as backup)
- [ ] Have successors handle a simulated incident or debug a real issue
- [ ] Have successors explain each system to someone who wasn't in the sessions
- [ ] Identify gaps revealed during verification exercises
- [ ] Schedule additional sessions to fill identified gaps
- [ ] Review and clean up all documentation created during transfer
- [ ] Ensure all recordings are organized and accessible
Information to Capture for Each Critical System
Architecture & Design
- [ ] How major components connect to each other
- [ ] Data flow diagrams showing how information moves through the system
- [ ] Integration points with external systems and APIs
- [ ] Key dependencies and why they were chosen
Historical Context
- [ ] Why the system was built this way (design rationale)
- [ ] What alternatives were considered and rejected
- [ ] What approaches didn't work in the past
- [ ] What constraints shaped the current design
Operations
- [ ] Step-by-step deployment procedure
- [ ] Key monitoring dashboards and what to watch for
- [ ] Common issues and how to debug them
- [ ] Who to contact for upstream/downstream dependencies
- [ ] Incident response playbook for common failure modes
Tribal Knowledge
- [ ] Known quirks and gotchas
- [ ] Workarounds for known bugs
- [ ] Implicit assumptions in the code
- [ ] Things marked "don't touch" and why
- [ ] Undocumented dependencies or behaviors
Access & Credentials
- [ ] Services and systems the departing engineer has access to
- [ ] Credentials they personally hold that need to be rotated
- [ ] Shared accounts or API keys only they know about
- [ ] Any personal accounts used for work purposes
First Week After Departure
- [ ] Verify successors can handle routine tasks independently
- [ ] Confirm someone can respond to incidents in previously owned areas
- [ ] Test that documentation is usable by someone who didn't attend sessions
- [ ] Track questions that no one can answer (these are knowledge gaps)
- [ ] Document any information learned from contacting the former engineer
- [ ] Identify any critical gaps that emerged unexpectedly
First Month After Departure
- [ ] Monitor for bugs that take longer to fix than expected
- [ ] Track incidents with extended resolution time in affected systems
- [ ] Note areas where the team seems to be guessing rather than knowing
- [ ] Update bus factor calculations to reflect the new reality
- [ ] Address any newly single-author files with cross-training
- [ ] Document lessons learned: what would you do differently next time?
- [ ] Update onboarding materials based on what knowledge was hardest to transfer
Limited Time Emergency Checklist
When you have less than two weeks or face immediate departure, focus only on these essentials:
- [ ] Identify revenue-critical systems where they're the sole expert
- [ ] Record video walkthroughs of critical systems (even rough recordings help)
- [ ] Document deployment procedures for systems that must be deployed regularly
- [ ] Capture credentials and access information
- [ ] List what you know you don't know (make gaps visible)
- [ ] Freeze risky changes to affected systems
- [ ] Communicate increased risk to stakeholders transparently
- [ ] Consider whether external consultants could help bridge critical gaps
How ContributorIQ Supports Departure Planning
When a key engineer gives notice, the first hours matter. ContributorIQ's Departure Impact Analysis automates the assessment described in this checklist by instantly calculating the effect of a specific contributor's departure across all repositories. It identifies which systems will lose their primary author, which files will become orphaned, and how bus factor will change for each affected repository. Instead of spending Day 1 manually pulling contributor profiles and cross-referencing git logs, your engineering manager can generate a complete impact report and move directly to planning the transfer.
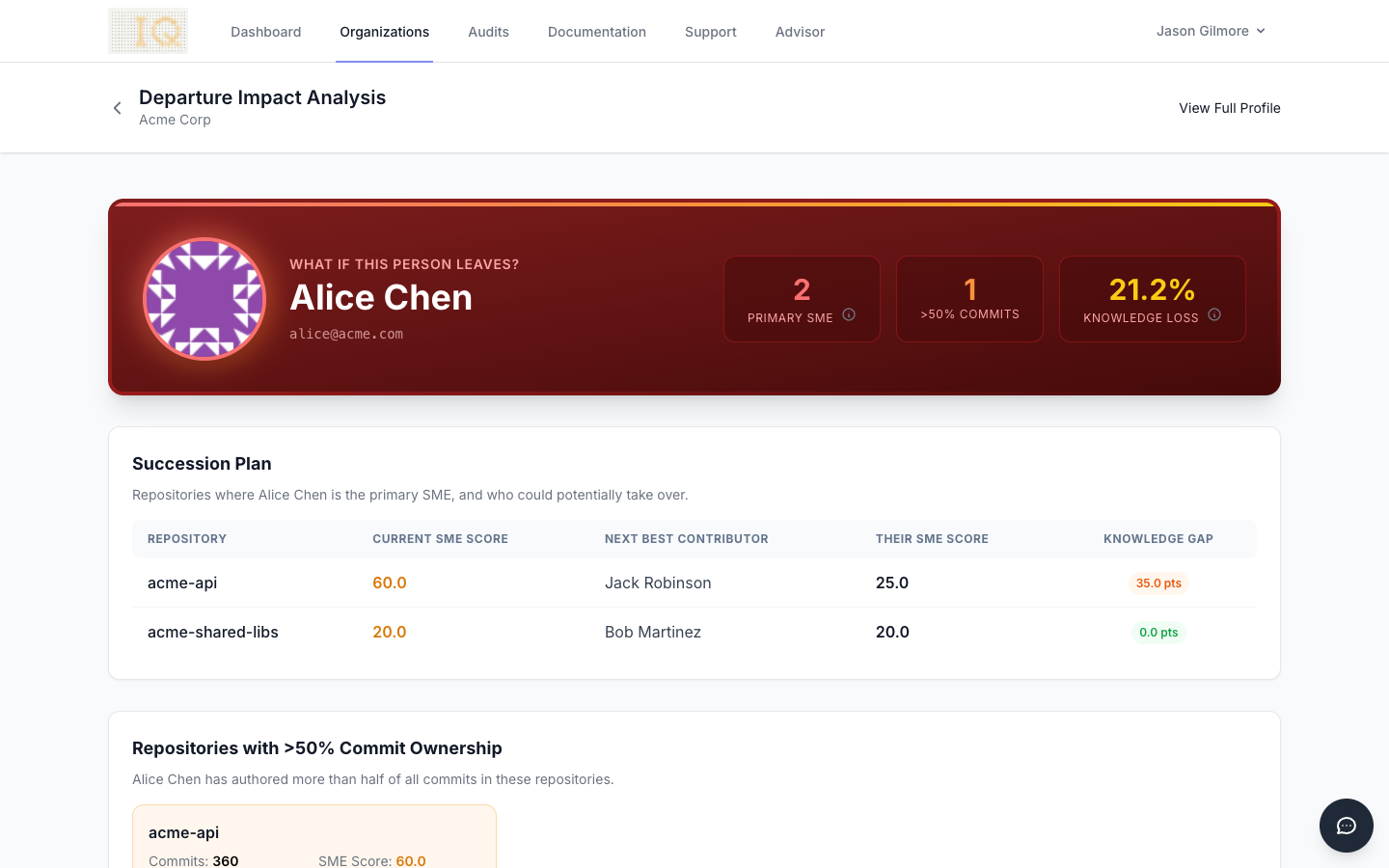
The Contributor Detail view provides the granular data you need for prioritization. It shows each contributor's Degree of Authorship scores across files, their lifecycle classification, and their activity trends over time. For the departing engineer, this view makes it clear exactly which systems they own most deeply and where knowledge gaps will emerge. For potential successors, it reveals who already has partial familiarity with at-risk areas and could ramp up most quickly.
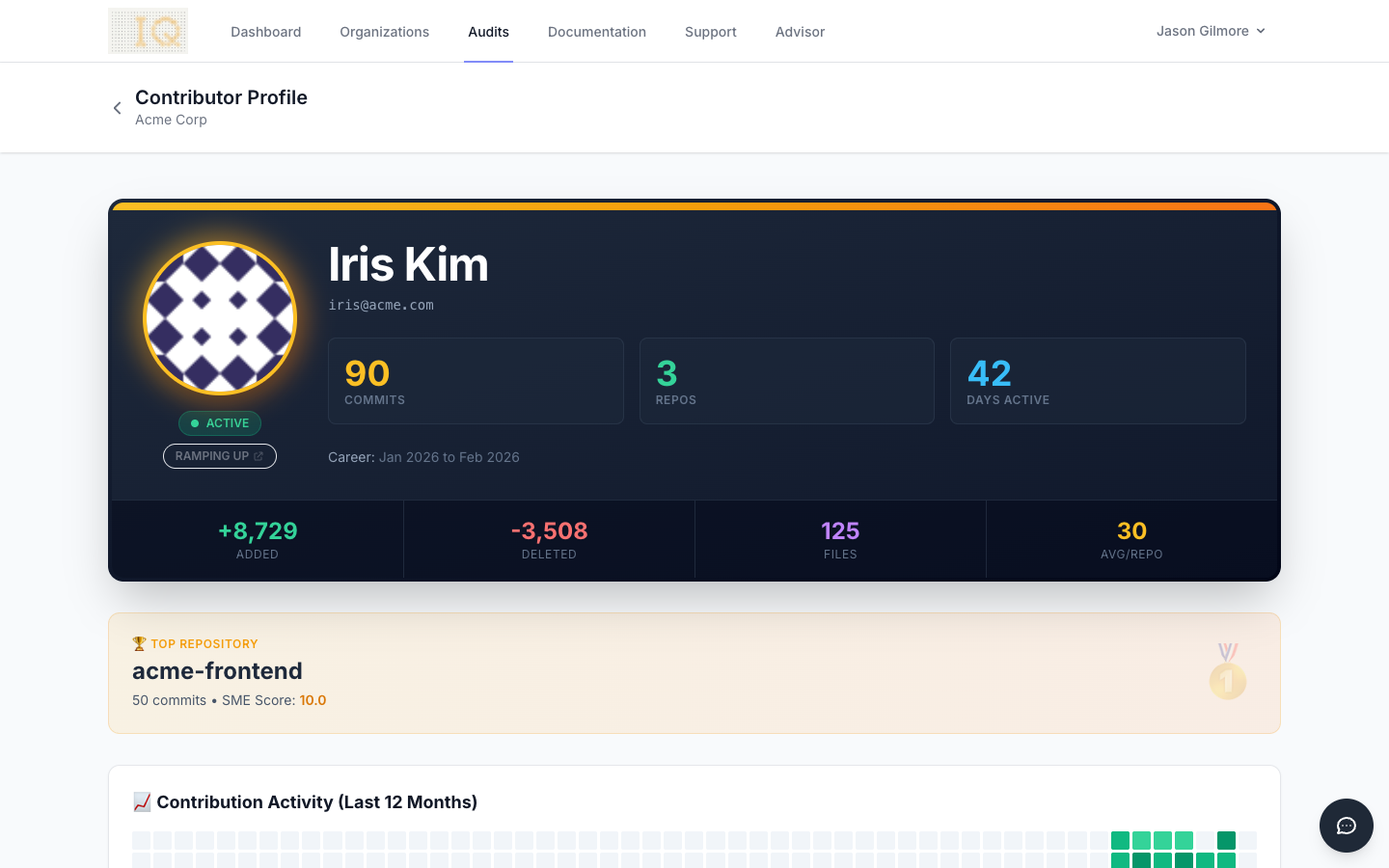
By combining these views, ContributorIQ turns a stressful departure into a data-driven transition. You can prioritize transfer sessions based on actual ownership concentration, identify the best successors using real contribution data, and track whether knowledge gaps are closing during the notice period.
Conclusion
Engineer departures are inevitable. Panic is optional.
With a systematic approach, you can assess the impact quickly, prioritize what matters most, transfer knowledge effectively, and verify that successors can actually do the work before the expert walks out the door.
The goal isn't preventing departures. It's ensuring they're manageable transitions rather than organizational emergencies. Every departure handled well builds organizational muscle for the next one.