Key Person Risk in Engineering: Spot & Reduce It
When one engineer holds critical knowledge, the company is one resignation from disaster. How to spot key person dependency and reduce it before it bites.
- Introduction
- How Key Person Dependencies Develop
- Recognizing Key Person Dependencies
- The Business Impact
- Measuring the Risk
- Mitigation Approaches
- Balancing Expertise and Distribution
- Warning Signs Worth Watching
- Putting It Into Practice with ContributorIQ
- Conclusion
Introduction
Every engineering team has experienced the moment: someone asks a question about how the authentication system works, and everyone instinctively turns to the same person. "Only Sarah knows how that works" has become such a common phrase that it barely registers as a warning sign anymore.
A key person dependency exists when critical knowledge or capabilities concentrate in a single individual. In software development, this typically means one engineer holds unique understanding of important systems, understanding that others cannot easily replicate because it's built over years of working with complex, evolving code.
The risk is straightforward: when that person is unavailable, whether for a vacation, a sick day, or a new job offer, the organization's ability to maintain and develop those systems drops dramatically. Software knowledge exists primarily in people's heads, not in the code itself or its documentation. When the person leaves, the knowledge leaves with them.
How Key Person Dependencies Develop
Some dependencies form naturally. The founder who wrote the original architecture fifteen years ago still carries context that no documentation could fully capture. Long-tenured engineers accumulate knowledge about historical decisions, undocumented workarounds, and customer-specific edge cases simply by being present as the system evolved. Specialists in niche technologies (legacy protocols, specialized algorithms, regulatory-specific implementations) become critical by virtue of expertise that's difficult to hire.
Other dependencies form through organizational patterns. When teams work in silos without cross-functional collaboration, knowledge stays isolated in small groups or individuals. When code reviews are optional or superficial, changes happen without transferring understanding to anyone else. When documentation is treated as nice-to-have rather than essential, tribal knowledge becomes the norm. When companies grow rapidly without investing in onboarding, new engineers can't penetrate the accumulated complexity.
Perhaps the most common pattern is the engineer who "owns" by default, the person who never says no when a question comes up about an unfamiliar system. Over time, work gravitates to them not because they asked for it, but because no one else volunteers. Their helpfulness creates organizational fragility.
Recognizing Key Person Dependencies
The behavioral signs are often obvious once you start looking. Listen for phrases like "only Sarah knows how that works" or "we need to wait for Mike to get back from vacation." Watch for anxiety when specific people take time off. Notice when one person appears on every critical incident call, or when questions consistently route to the same person regardless of topic.
Quantitative indicators can make the problem concrete. A bus factor of 1 means only one contributor has significant ownership of a system, so a single departure could cause serious problems. High concentration of Degree of Authorship scores indicates one person's fingerprints are all over the codebase. Large numbers of single-author files mean extensive code that no one else has ever touched. When one person accounts for more than 40% of commits to a repository, that's a concentration worth examining.
The challenge is that many of these patterns feel normal. Of course senior engineers know more than juniors. Of course the person who built a system understands it best. The question is whether "understands it best" has crossed into "understands it alone."
The Business Impact
The operational impact is felt daily, even before anyone leaves. Key persons become bottlenecks, constantly interrupted for their expertise, unable to focus on the work they're actually assigned. Vacation planning becomes complicated: can we ship this release if Alex is out? Incidents stretch longer because they wait for specific people to wake up or return from time off.
Strategic risks accumulate more quietly. Retention becomes delicate because employees who know they're irreplaceable gain leverage, and they know it. Acquirers discount companies with high key person risk because the value depends on specific individuals staying after the deal closes. Growth becomes constrained because you can't scale faster than your key person can review, advise, and unblock.
The financial impact shows up in unexpected places. Irreplaceable employees can command above-market compensation because the alternative is accepting the risk they might leave. When they do leave, organizations pay for expensive consultants or accept project delays. Bug fixes that should take hours take days because no one understands the relevant code.
Measuring the Risk
Making key person risk concrete requires looking at it from multiple angles.
At the repository level, calculate bus factor for each system. Identify which repositories have a bus factor of 1 and note which contributor is the sole expert. Rank these by business criticality, since a bus factor of 1 on your billing system is much more concerning than on an internal admin tool.
At the contributor level, list all the repositories where each engineer has high ownership. Count how many critical systems they're the sole expert on. Consider their lifecycle stage, because a key person at peak engagement presents different risk than one who appears to be winding down.
At the file level, identify all single-author files and calculate what percentage of your codebase falls into that category. Map file ownership to specific contributors to see who would leave the biggest gaps.
Combining these perspectives into a risk score for each contributor helps prioritize where to focus. Weight the number of systems they solely own, the business criticality of those systems, their engagement trajectory, and any signals about retention risk like recent vesting or short tenure.
Mitigation Approaches
Short-term tactics focus on reducing immediate exposure. Prioritize documentation for systems owned by high-risk key persons. Focus not on comprehensive specifications, but on the knowledge that exists only in their heads: architecture decisions, operational procedures, known issues and their workarounds. Pair the key person with a designated backup who shadows them on changes, joins them on-call, and participates in all relevant discussions. Require code reviews that demonstrate understanding, not just approval, with rotating reviewers to spread knowledge. Record knowledge transfer sessions, because video walkthroughs and documented Q&A create artifacts that outlast any individual.
Longer-term strategies address the patterns that create dependencies. Rotate ownership deliberately rather than letting expertise calcify in individuals. When hiring, consider where expertise gaps exist and how new engineers can become second experts on critical systems. Build cross-training into sprint cycles rather than treating it as optional overhead. Track key person metrics quarterly and make improvement a team responsibility.
The cultural shift matters as much as the tactical changes. Don't reward knowledge hoarding, even unintentional hoarding that comes from being helpful. Promote engineers who build capable teams, not just individual contributors who accumulate dependencies. Celebrate when systems become maintainable by multiple people, not when they become controlled by experts.
Balancing Expertise and Distribution
It's worth emphasizing that deep expertise is valuable. The goal isn't to eliminate specialists or pretend everyone can know everything equally well. The distinction is between healthy specialization and dangerous concentration.
A healthy pattern looks like: "Sarah is our best database expert, and Bob can also handle most database issues." A dangerous pattern looks like: "Only Sarah can deploy the database, and if she's not available we have to wait."
The backup doesn't need expertise equal to the primary expert. They need enough understanding to continue work while ramping up, with documentation and recorded sessions to support their learning. The goal is continuity, not duplication.
Warning Signs Worth Watching
Some organizational signals suggest key person risk is elevated. Projects stalling when specific people take vacation. New hires struggling to contribute to certain systems even after months of onboarding. The same person appearing on every critical incident.
Individual warning signs matter too. A key person whose calendar is perpetually full with questions from others. Someone expressing frustration about being the only one who knows things. An engineer who has fully vested and hasn't been given new reasons to stay. Signs of burnout in someone the organization depends on heavily.
System-level indicators include documentation that's out of date or nonexistent, git history showing only one active contributor, code reviews that rubber-stamp rather than engage, and missing tests (which serve as a form of documentation themselves).
Putting It Into Practice with ContributorIQ
Identifying key person dependencies manually requires cross-referencing bus factor data, commit histories, and file ownership across every repository in your organization. ContributorIQ automates this analysis end-to-end. By connecting to your GitHub organization, it calculates Degree of Authorship for every file, identifies sole experts, and surfaces the contributors whose departure would create the greatest impact.
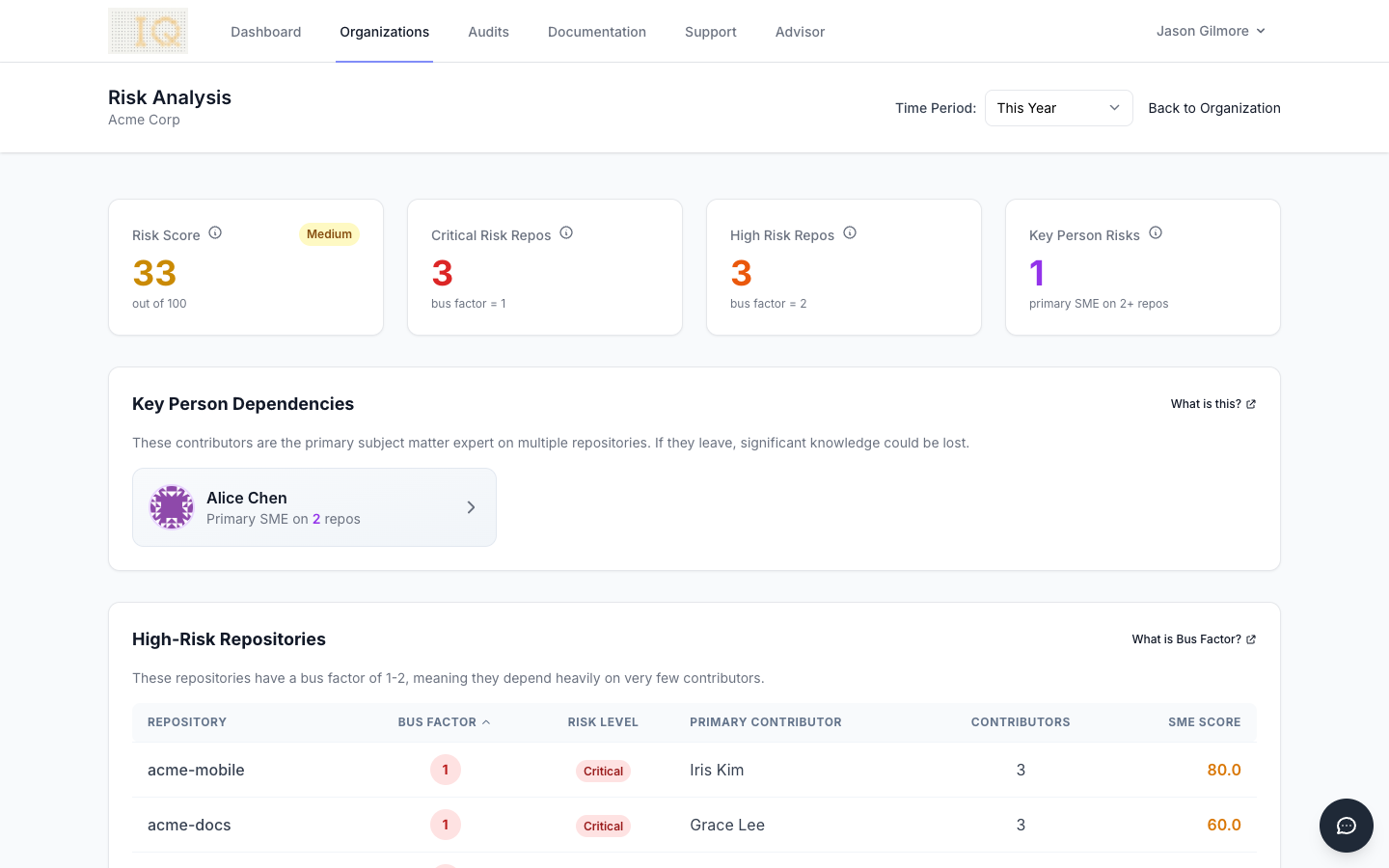
The organization risk overview dashboard consolidates these findings into a single view. You can see which repositories have a bus factor of 1, how many single-author files exist, and where orphaned code is accumulating. This makes it straightforward to prioritize mitigation efforts: focus knowledge transfer on the systems and contributors that represent the highest organizational risk.
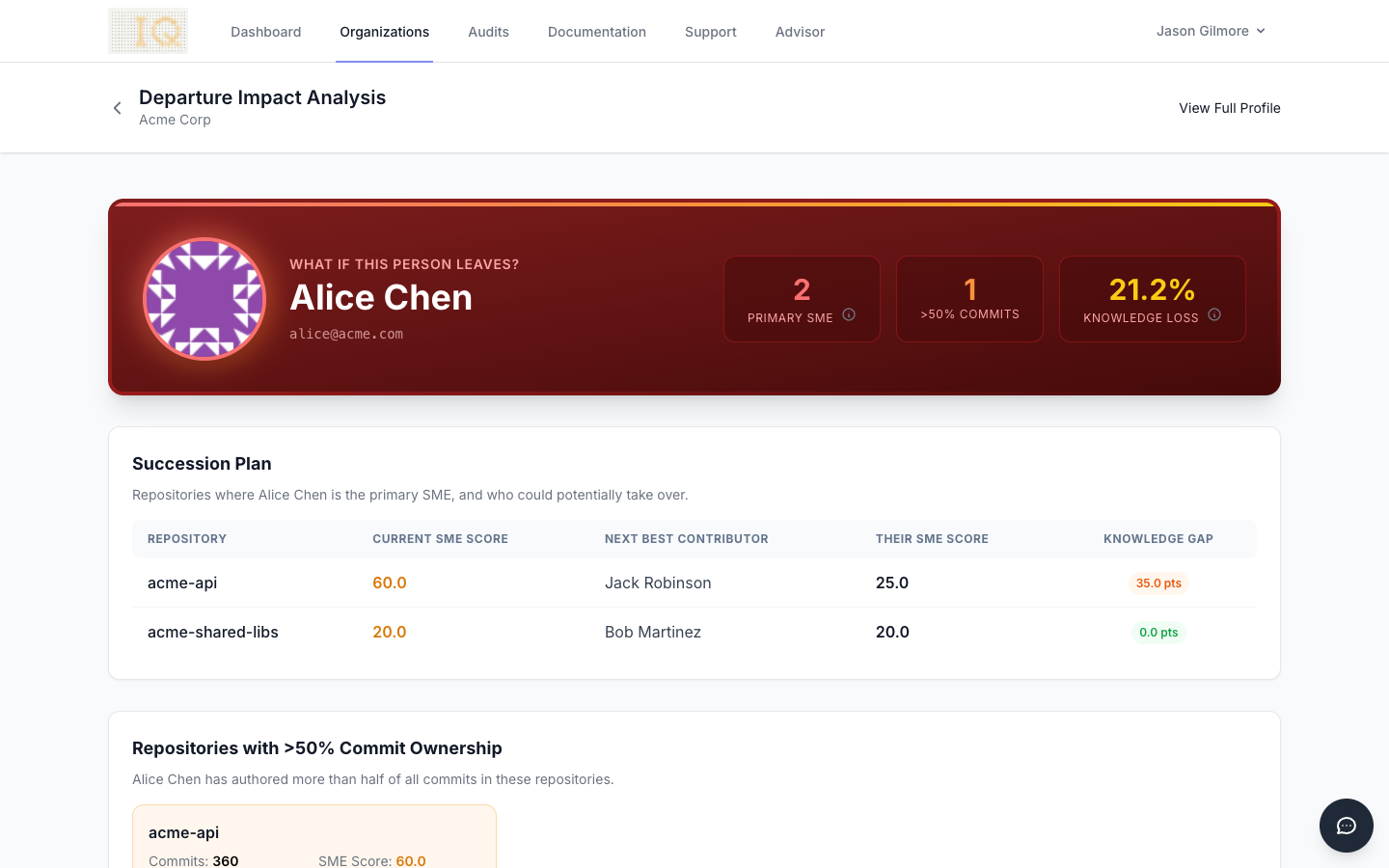
ContributorIQ also provides departure impact analysis for individual contributors. Select any team member to see exactly which repositories they solely own, how many files would become orphaned if they left, and the overall risk score associated with their departure. This contributor-level view transforms abstract risk discussions into concrete planning conversations, whether you are preparing for a known transition or building contingency plans proactively.
Conclusion
Key person dependency is a manageable risk, but managing it requires deliberate action. The cost of ignoring it remains invisible until someone leaves and the hidden fragility becomes painfully apparent.
Start with measurement. Calculate bus factor across your repositories. Identify contributors with high concentration using DOA analysis. Prioritize the risks based on business criticality.
Then take action. Document the critical knowledge that exists only in people's heads. Build backup expertise through pairing and meaningful code reviews. Make knowledge distribution a tracked metric that teams are accountable for improving. Learn to recognize the warning signs of knowledge concentration early, and address the cultural patterns like hero culture that create key person dependencies in the first place.
The investment pays off when your next resignation notice doesn't trigger a crisis, when it's simply a transition to manage rather than an emergency to survive.